
|
|
|
Introduction
Most artificial neural networks are used for recognizing and classifying patterns. For example, some have been trained to watch features in the stock market and recommend when to buy and sell stocks. But recognizing patterns is not the only function of animal and human nervous systems. They also exhibit goal-seeking behavior. In this tutorial, a mouse will be seeking a goal in the form of a piece of cheese in a room at the end of a maze.
This is not going to be a simple straightforward maze: from this room, take this door and get to the next room, etc. That kind of maze could be handle very efficiently by a mechanism called a finite state machine. Instead, there is a twist to the problem: the mouse will have to remember something from the beginning of the maze to help it achieve the goal at the end of the maze. Information about a situation that improves specific decisions is considered context information. For example, if you are given a package and told to deliver it to 508 Main Street you might naturally assume that it is in the town or city that you are currently in. That would be the context of the address. However, if you are working for a delivery service that has a broad base of operations, you would want to make sure of the city, otherwise you might deliver the package to the correct address in the wrong city. For the mouse, the information at the beginning of the maze is going to form the context for its decision at the end of the maze. That is what it has to learn in addition to how to get through the maze.
There is a type of neural network called a recurrent neural network that retains information about past inputs by feeding the neuron outputs back into the network, but information from events that happen in the more distant past degrades as the connection weights are updated and it loses influence over later outputs. In order to solve the context problem, a neural network designed for retaining context state information over a duration of time is required. The neural network that will be used to do the job is the goal-seeking neural network Mona.
The Mona Neural Network
Mona has a simple interface with its environment: it accepts sensory information as input and outputs responses to the environment. The task is to produce a sequence of responses that will navigate it toward goals. What are goals? Mostly they are sensory states that reduce Mona's needs, much like food reduces hunger.
Events can originate from sensors, responses, or internal states, calling for three types of neurons. Neurons attuned to sensors are receptors, and those associated with responses are motors. Mediator neurons coordinate sensory/motor events and other mediators. Mediators can be structured in hierarchies representing environmental contexts, in which state information is captured in a mediator's enablement. Enablement is used to direct the flow of motive through the network into motor neurons that will drive the system toward goals.
To illustrate, here is a very simple example. Consider a mouse that has been out foraging in a house and now wishes to return back to her mouse-hole in a certain room. For the sake of keeping peace with her fellow mice, she must not make the mistake of going into a hole in another room.
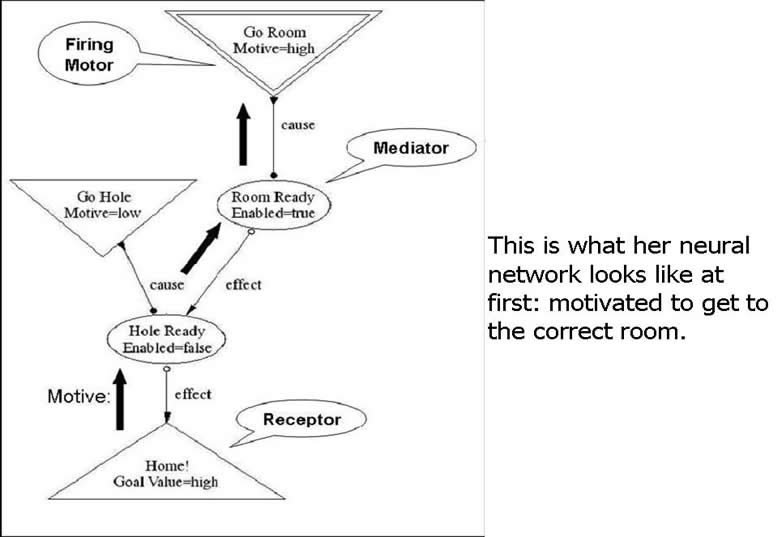
The three types of neurons are shown in the above figure, which depicts the initial state of the mouse's neural network. The "Go Room" motor (inverted triangle) is firing (double outline) to take the mouse into the correct room. "Go Room" is a cause event of the "Room Ready" mediator (oval); its effect event is another mediator, "Hole Ready". The cause for "Hole Ready" is a different motor neuron, "Go Hole", and its effect is a receptor (triangle) that will fire when the mouse gets into her hole. The "Home!" receptor is also a goal, as indicated by the Goal Value annotation.
How does this network orchestrate the proper sequence of actions? Note the arrow carrying motive through the network. The motive is propagating from the goal through the network into the "Go Room" motor neuron. The reason for this has to do with the enablement state of the mediators. The "Hole Ready" mediator is not enabled, reflecting the constraint that the mouse must be in the correct room before going to her hole. Because of this, motive is channeled by the "Hole Ready" mediator to a higher mediator, "Room Ready". "Room Ready" is already enabled, meaning that there is a good chance that if its cause fires, its effect can also be made to fire. So it channels motive into its cause, which in this case is a motor, causing it to fire.
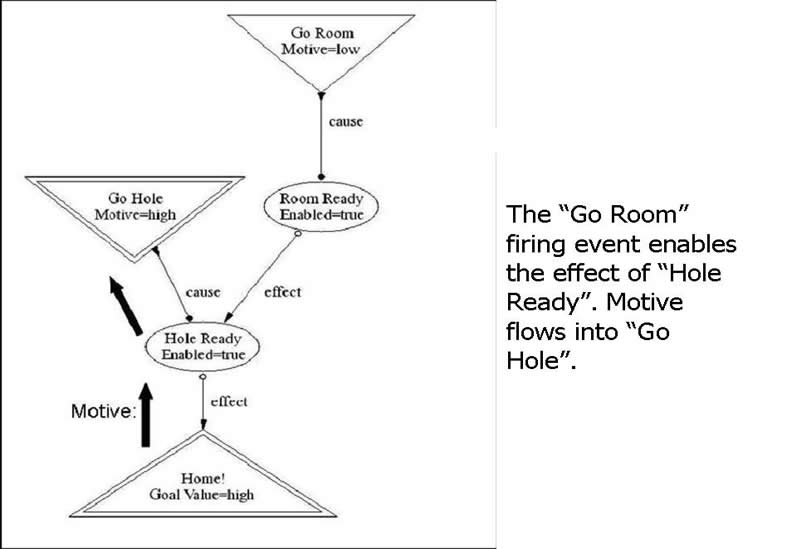
After the "Go Room" motor fires, presumably the mouse is in the correct room, signified by the "Hole Ready" mediator now becoming enabled. In the above figure, "Hole Ready" then channels motive into its cause, firing it. The "Home!" receptor then senses that the mouse is in her hole and fires.
One way to understand the enablement idea is to put yourself in the position of the "Hole Ready" mediator. At first you are not sure that helping your cause to fire will result in your effect firing, reflecting the notion that the mouse is not sure at first which room she is in. So the sensible thing to do is to ask some mediator to put you in the correct room (context). This is the "Room Ready" mediator. "Room Ready" can enable "Hole Ready" when it successfully fires "Go Room". This process is discussed in more detail later. Now sure of the room, "Hole Ready" can help its cause fire to get the mouse into the hole.
How Mona Learns
Mona keeps a history of firing neurons that serves as a basis for hypothesizing new cause and effect relationships that are incarnated as new mediators. How far back in time the history is kept is a system parameter. Furthermore this can vary based on the hierarchical level of mediators, allowing higher level mediators to associate events more distantly separated in time. For the maze problem, the history was set to allow the highest possible mediators to oversee events spanning the entire maze, thus allowing the correct door choice to be remembered.
Another essential learning activity besides the generation of new mediators is the evaluation of existing ones. A firing cause neuron generates a wager on the firing of the effect neuron. Wagers can temporarily change the enablement of a a lower level mediator; this is how context information comes into play in formulating responses. In effect, a wager represents a bet that an effect will fire given that its associated cause has fired. The base enablement (i.e., without any context) of a mediator is the fraction of successful wagers:
base-enablement = #successful wagers / #wagers
The Maze Context-Learning Problem
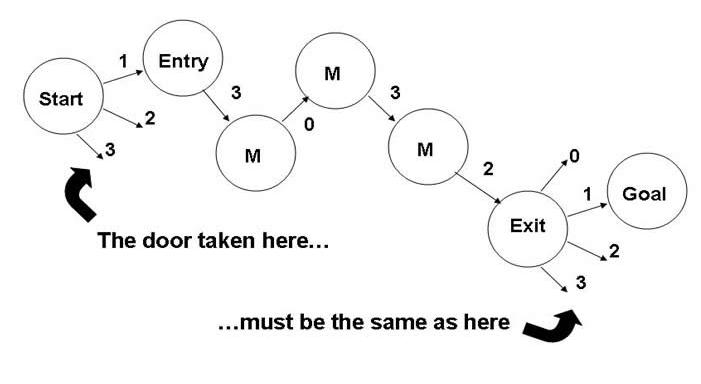
The figure below depicts an example of a maze.
In going from the maze Entry room to the maze Exit room all the M rooms look exactly the same, so the mouse must remember a specific sequence of doors.
Each time the mouse starts a maze the door leading from Start to Entry may change, but it must remember and choose the particular door in order to get from room Exit to the Goal room. This is the context information.
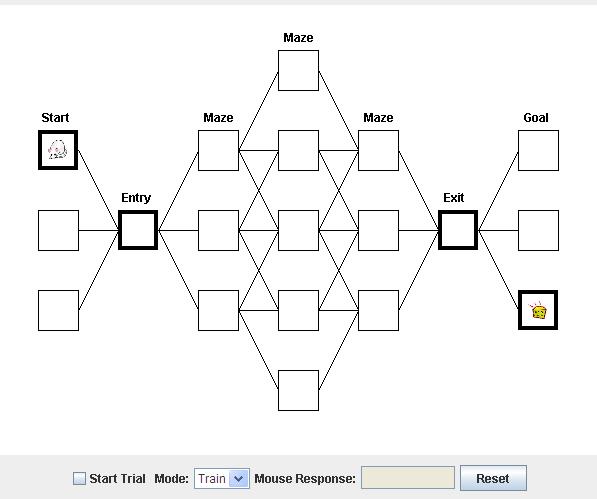
The Maze Simulator
The best way to familiarize yourself with how the mouse will learn the maze is to actually train a mouse to do it using the simulator below.
The simulator has two modes, train and run. In train mode, the mouse will be forced to move along a path that you define by selecting rooms. The point is to allow it to learn a sequence of doors to take. In run mode the mouse is free to determine which door to take. So for example, you could create a path all the way from where the mouse is to the cheese, run a few training trials, and then see if the mouse has learned this path. I suggest doing this now.
That seems simple enough. But it isn't the point that we are after, since this is just a long chain of doors. In order to prove that context information can be learned you will first train the begin/end door correspondences, then train and re-train different interior maze paths (Entry to Exit rooms). If interior paths can be switched and the door correspondences retained, this means that the door correspondence learning is independent of the interior path learning, implying that some state information is being retained in the neural network during the navigation of the maze. Later on we'll look at a few of these neurons.
The figure below shows how the door 0 correspondence can be trained. First click reset to make the mouse forget the first experiment, then run this for about 4-5 trials in order to establish the memory. The other doors can be trained in a similar fashion.
Now train an interior path of your choice for a few trials. Below is one example.
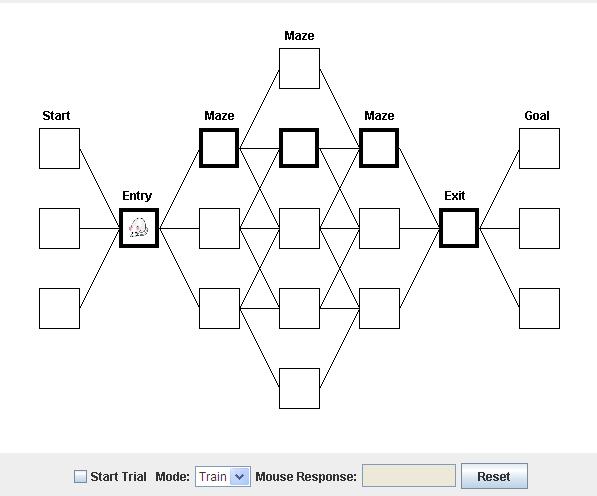
Now see if the mouse can make it all the way to the cheese:
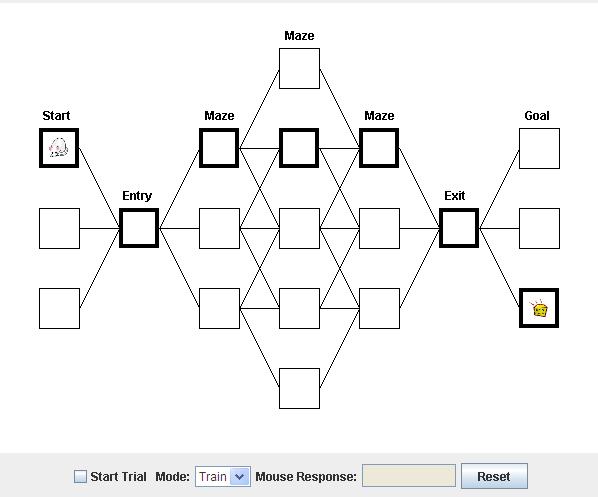
Try some other Start rooms. If it makes an incorrect choice, just retrain a little bit and re-run. Before long the mouse will know the whole maze!
Now to switch the interior path. Train a new interior path, for example the one shown below:
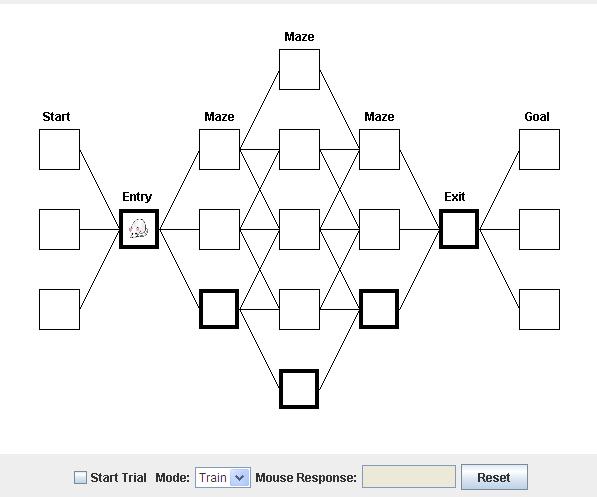
Now go back and try the entire end-to-end path with the new interior. If the mouse shows some initial fondness for the old path and makes some mistakes just be patient. It will get better on the next trial!
A Look Inside the Mouse's Brain
We will now take a look at a few of the neurons in the mouse's brain to see how the context information is being used. Specifically, we will look at the neurons involved in a door correspondence at the beginning and end of the maze. But first, more diagrammatic definitions:
The initial state of the Door 0 correspondence neurons is shown below. The "Bridge Mediator" associates its cause "Start Mediator" at the beginning of the maze and its effect "Goal Mediator" at the end of the maze. Note that "Goal Mediator" is not fully enabled, signifying the lack of certainty at this point that Door 0 is the door to take at the Exit room. This uncertainty is also reflected in the modest motive value channeled to the "Open Door 0" motor neuron.
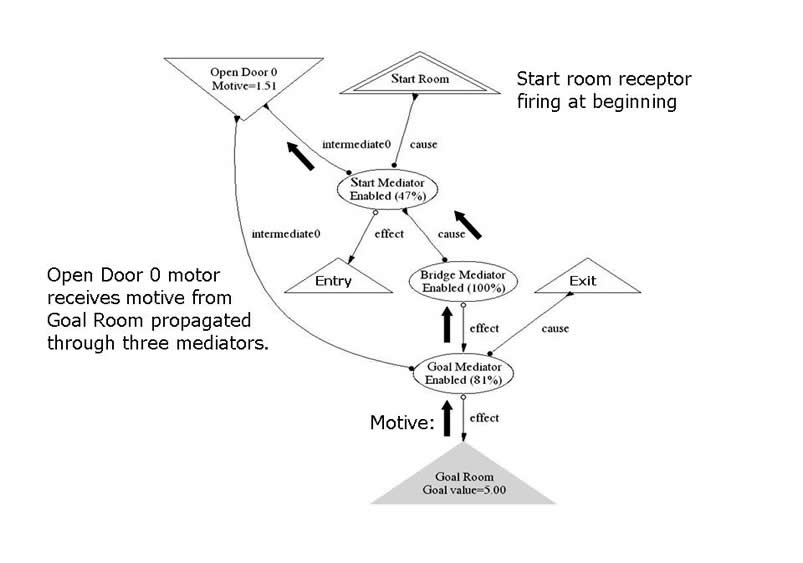
The figure below shows Door 0 being taken, indicated by the firing of the associated motor neuron. The door opens and the mouse senses the Entry room, indicated by the Entry receptor firing. The "Goal Mediator" is now fully enabled since it is certain that it mediates the correct choice.
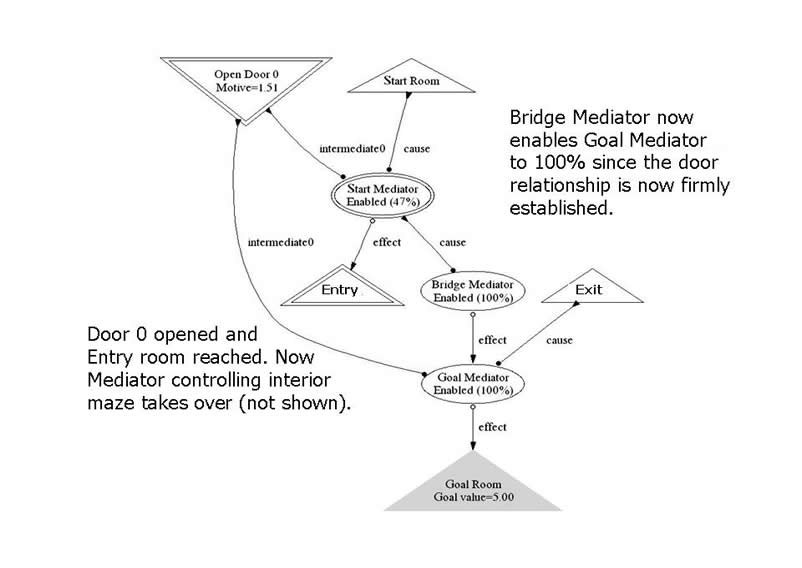
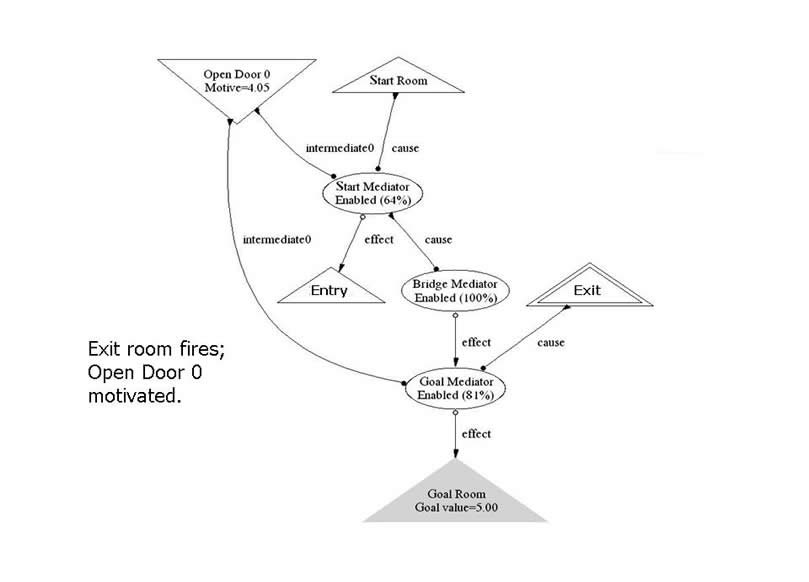
While the interior of the maze is navigated, the bridge assembly of neurons is dormant; they are independent activities.This is why the interior path can be changed and re-learned without affecting the bridge neurons. The interior neurons know how to get from the Entry to the Exit room, and motive flows through them to accomplish this. Eventually the Exit room receptor fires. Now a strong motive value is channeled into the "Open Door 0" through the enabled "Goal Mediator", after which it returns to its former "base" enablement value.
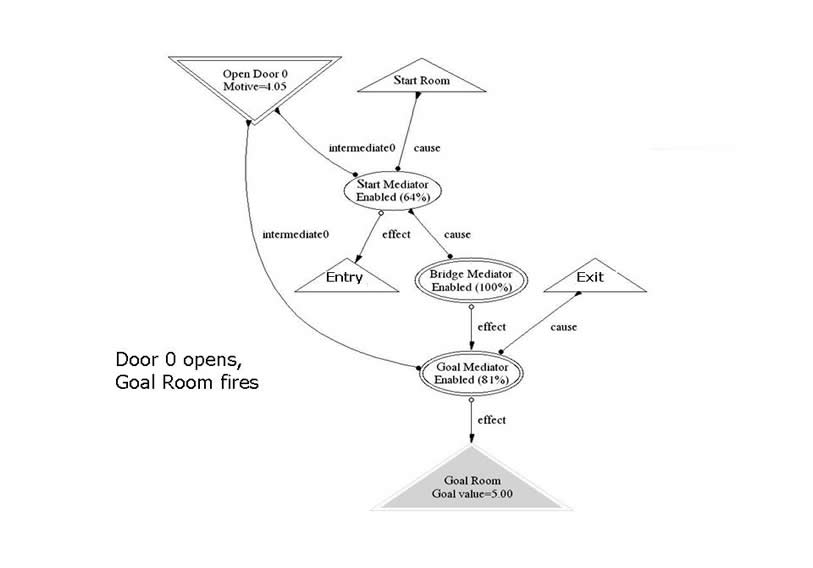
Door 0 is taken, and the Goal Room is reached.
Further Reading
T.E. Portegys, "Goal-Seeking Behavior in a Connectionist Model",
Artificial Intelligence Review. 16 (3):225-253, November, 2001.
(Paper)
T.E. Portegys, "An Application of Context-Learning in a Goal-Seeking Neural Network ",
The IASTED International Conference on Computational Intelligence (CI 2005).
(Paper)